白话科普 | DeepSeek的蒸馏技术到底是什么?90%的人都没搞懂,但西方却抓着不放!
引言:AI领域的“炼金术”——模型蒸馏在人工智能领域,大型语言模型(LLM)无疑是近年来最耀眼

引言:AI领域的“炼金术”——模型蒸馏在人工智能领域,大型语言模型(LLM)无疑是近年来最耀眼的技术突破之一。然而,这些拥有数百亿甚至上千亿参数的庞然大物,虽然性能卓越,却也因其高昂的计算成本和资源需求而难以普及。如何让这些“巨无霸”级别的模型普及到大众手中?答案就在于一种被称为知识蒸馏的技术。
知识蒸馏是一种将复杂的大模型(教师模型)的知识迁移到小型高效模型(学生模型)的方法。通过这种方式,小模型不仅能够继承大模型的强大能力,还能以更低的成本、更快的速度运行。这就像是一位经验丰富的老师将自己的智慧传授给学生,使他们能够在有限的时间内掌握核心技能。
今天,我们将深入探讨这一技术,并聚焦于一家名为DeepSeek的公司。这家公司凭借其创新的蒸馏技术,在短短几个月内迅速崛起,成为AI领域的明星企业。本文将从基础知识入手,逐步揭示DeepSeek如何利用蒸馏技术实现技术裂变,并探讨这项技术对未来AI发展的深远影响。
第一章:什么是知识蒸馏?——从“老师教学生”说起
1.1 知识蒸馏的基本原理
想象一下,一位经验丰富的老师正在指导他的学生。这位老师已经积累了大量的知识,但他不可能把所有细节都直接告诉学生;相反,他会总结出一些关键点,让学生更容易理解和应用。在AI中,这种过程就是知识蒸馏。
具体来说,知识蒸馏包括以下几个步骤:
- 训练教师模型:首先需要一个性能强大的大型模型作为“老师”,比如DeepSeek 671B大模型。这个模型通常经过海量数据的训练,具备极高的准确率。
- 准备学生模型:接下来设计一个小巧灵活的学生模型,比如DeepSeek 1.5B小模型。这个模型结构简单、参数少,但潜力巨大。
- 知识传递:学生模型通过模仿教师模型的输出或中间特征来学习。例如,教师模型可能会生成一个包含多个可能性的概率分布(称为“软标签”),而学生模型则尝试复制这个分布。
- 优化调整:最后,通过一系列损失函数和训练策略,确保学生模型尽可能接近教师模型的表现。
1.2 为什么我们需要知识蒸馏?
尽管大模型性能优越,但它们存在明显的局限性:
- 高计算成本:运行一次推理可能需要数十甚至上百个GPU,普通用户根本无法负担。
- 内存占用大:许多设备(如手机、嵌入式系统)根本没有足够的存储空间支持这些模型。
- 实时性差:由于计算量庞大,大模型往往无法满足实时响应的需求。
相比之下,经过蒸馏的小模型则可以轻松部署在各种场景中,无论是智能手机还是自动驾驶汽车,都能流畅运行。更重要的是,这些小模型还保留了大部分原始模型的能力,真正实现了“鱼与熊掌兼得”。
第二章:DeepSeek的蒸馏技术——站在巨人肩膀上的飞跃
2.1 DeepSeek是谁?它为何如此重要?
DeepSeek是一家专注于AI模型优化的公司,其核心技术正是基于知识蒸馏。该公司开发了一系列高效的蒸馏模型,例如DeepSeek-R1-Distill-Qwen系列,这些模型在多个基准测试中表现优异,甚至超越了一些未蒸馏的大模型。
那么,DeepSeek究竟做了什么特别的事情呢?
2.2 数据蒸馏与模型蒸馏结合——双管齐下的创新
传统的知识蒸馏主要关注模型层面的迁移,即学生模型模仿教师模型的输出。然而,DeepSeek另辟蹊径,将数据蒸馏引入其中,形成了独特的“双轨制”蒸馏方法。
数据蒸馏的作用
数据蒸馏是指通过对训练数据进行增强、伪标签生成等操作,提升数据的质量和多样性。例如,教师模型可以对原始图像进行旋转、裁剪等处理,从而生成更多样化的样本。这些高质量的数据为学生模型提供了更好的学习材料,使其能够更快速地成长。
模型蒸馏的优化
与此同时,DeepSeek还在模型蒸馏方面进行了大量创新。例如,他们采用了一种叫做监督微调(SFT)的方法,用教师模型生成的80万个推理数据样本对学生模型进行微调。这种方法避免了传统强化学习阶段的冗长训练,显著提高了效率。
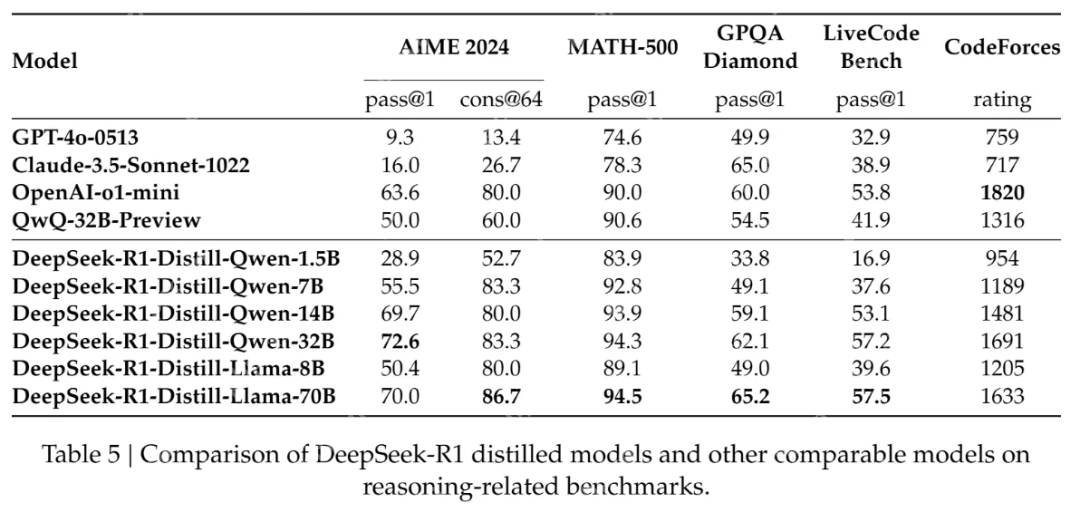
DeepSeek开源了基于不同大小的 Qwen 和 Llama 架构的几个提炼模型。这些包括:
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Llama-70B
2.3 高效知识迁移策略——不只是模仿,还有创造
除了上述两点,DeepSeek还提出了一系列高效的知识迁移策略,包括基于特征的蒸馏和特定任务蒸馏。前者通过提取教师模型中间层的特征信息,帮助学生模型更好地理解数据的本质;后者则针对不同的应用场景(如文本生成、机器翻译等)进行针对性优化。
这些策略使得DeepSeek的蒸馏模型在实际应用中表现出色。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024上实现了55.5%的Pass@1,超越了QwQ-32B-Preview(最先进的开源模型)。这样的成绩证明了蒸馏技术的巨大潜力。
第三章:蒸馏技术的核心数学基础——公式与算法详解
5.1 温度参数与软标签
在蒸馏过程中,温度参数 是一个关键因素。它用于调整教师模型输出的概率分布,使其更加平滑或陡峭。具体来说,教师模型的输出概率 可以通过以下公式进行调整:
[ q_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} ]
其中,( z_i ) 是教师模型的原始输出,( T ) 是温度参数。当 ( T > 1 ) 时,分布会变得更加平滑;当 ( T
5.2 KL散度与损失函数
为了衡量学生模型与教师模型之间的差异,蒸馏技术通常使用KL散度(Kullback-Leibler Divergence)作为损失函数的一部分。KL散度的公式如下:
[ D_{KL}(P || Q) = \sum_i P_i \log \left( \frac{P_i}{Q_i} \right) ]
其中,( P ) 是教师模型的输出概率分布,( Q ) 是学生模型的输出概率分布。通过最小化KL散度,学生模型可以更好地模仿教师模型的行为。
5.3 动态学习率调整
为了提高训练效率,DeepSeek采用了动态学习率调整策略。学习率 ( \alpha ) 的更新公式如下:
[ \alpha = \alpha_0 \cdot \left(1 - \frac{t}{T}\right)^p ]
其中,( \alpha_0 ) 是初始学习率,( T ) 是总训练步数,( t ) 是当前训练步数,( p ) 是一个超参数。通过这种方式,学习率会随着训练的进行逐渐减小,从而提高模型的收敛速度。
第四章:蒸馏技术的社会意义——从教育到产业变革
4.1 “教会学生,饿死师傅”的悖论
有人担心,知识蒸馏会导致技术垄断者失去竞争优势。但实际上,这种情况很难发生。因为即使模型开源,背后的数据、算法和硬件基础设施仍然构成了难以逾越的壁垒。
更重要的是,蒸馏技术实际上促进了整个行业的进步。通过共享知识,更多的企业和个人得以参与到AI的研发中,从而推动了技术创新的加速。
4.2 AI普惠时代的到来
蒸馏技术的最大贡献在于降低了AI的门槛。过去,只有少数科技巨头才能承担起研发和部署大模型的成本。而现在,任何一家初创公司甚至个人开发者都可以借助蒸馏技术构建自己的AI解决方案。
这种变化不仅仅局限于技术领域,还将深刻影响我们的日常生活。从智能家居到医疗诊断,从教育辅导到娱乐推荐,AI正以前所未有的速度渗透到各个角落。
如果你对这篇文章感兴趣,不妨点赞、分享或留言交流你的看法。让我们一起见证AI的无限可能!
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>










热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 剑道逍遥题材手游排行榜下载-有哪些好玩的剑道逍遥题材手机游戏推荐
- 类似苍云澜歌的游戏排行榜_有哪些类似苍云澜歌的游戏
- 2023铁血守卫手游排行榜-铁血守卫手游2023排行榜前十名下载
- Q群仙传题材手游排行榜下载-有哪些好玩的Q群仙传题材手机游戏推荐
- 类似魔力物语的手游排行榜下载-有哪些好玩的类似魔力物语的手机游戏排行榜
- 四海琉璃手游排行-四海琉璃免费版/单机版/破解版-四海琉璃版本大全
- 神途传奇系列版本排行-神途传奇系列游戏有哪些版本-神途传奇系列游戏破解版
- 鼎力三国题材手游排行榜下载-有哪些好玩的鼎力三国题材手机游戏推荐
- 阴阳双剑手游排行-阴阳双剑免费版/单机版/破解版-阴阳双剑版本大全
- 神行九歌游戏版本排行榜-神行九歌游戏合集-2023神行九歌游戏版本推荐
- 斗破修罗系列版本排行-斗破修罗系列游戏有哪些版本-斗破修罗系列游戏破解版
- 灭龙传奇排行榜下载大全-2023最好玩的灭龙传奇前十名推荐





